






旷视科技首席科学家孙剑:如何打造云、端、芯上的视觉计算 | CCF-GAIR 2018
- T大
原标题:旷视科技首席科学家孙剑:如何打造云、端、芯上的视觉计算 | CCF-GAIR 2018
雷锋网按:2018 全球人工智能与机器人峰会(CCF-GAIR)在深圳召开,峰会由中国计算机学会(CCF)主办,雷锋网、香港中文大学(深圳)承办,得到了深圳市宝安区政府的大力指导,是国内人工智能和机器人学术界、工业界及投资界三大领域的顶级交流盛会,旨在打造国内人工智能领域最具实力的跨界交流合作平台。

6 月 30 日,计算机视觉专场举行,会场现场爆满,不少听众站着听完了长达数小时的演讲。上午场的议题为“计算机视觉前沿与智能视频”,由香港科技大学助理教授、RAM-LAB 主任刘明担纲主持。在他的串联下,香港科技大学教授权龙、旷视科技首席科学家、研究院院长孙剑、云从科技联合创始人姚志强、臻识科技 CEO 任鹏、云飞励天首席科学家王孝宇以及商汤联合创始人林达华等学界、业界大咖进行了 6 场深度分享,既有计算机视觉技术的前沿研究动态,也有相关技术落地的具体方向。

孙剑博士在CCF-GAIR现场演讲
旷视科技首席科学家、研究院院长孙剑博士为大家带来题为 “云、端、芯上的视觉计算”的精彩演讲。孙剑认为,计算机视觉简单讲就是使机器能看,旷视科技希望能够做到“赋能亿万摄像头”,让应用在所有领域的摄像头都具备智能,不管是在云、端还是在芯上。
计算机视觉的发展史就是研究如何表示图像的历史。深度学习流行之前,最好的办法是基于特征的,从图像里抽取特征,再进行分析;但是这个方法有两个大缺点:首先,该方法完成的非线性变换次数非常有限;其二,大多数参数都是人工设计的,包括 Feature。深度神经网络的办法弥补了手工设计特征的缺陷,整个非线性变换可以做非常多次,换句话说可以很深,所以特征表示能力非常强,并且可以自动地联合训练所有参数。孙剑博士在微软时提出 152 层的 ResNet,第一次在 ImageNet 大规模图像分类任务上超过了人的能力。
接着,孙剑博士从计算机平台的角度对出现的各种神经网络结构进行了分类:GoogleNet、ResNet 在“云”上;MobileNet 以及旷视提出的 ShuffleNet 属于“端”这一类;BNN、XNOR Net 和旷视提出的 DorefaNet 则是在“芯”上。针对目前分平台设计相关网络的现状,孙剑相信未来会有一个“MetaNet 出现,能够统一解决各个平台上的神经网络设计和优化问题”。
最后,孙剑简单介绍了旷视在云、端、芯三个平台上的计算机视觉应用,包括人脸识别、车辆识别、人脸支付、智慧安防、智慧金融、城市大脑、仓储物流、新零售等。

以下为孙剑演讲全文,雷锋网进行了不改变原意的编辑。
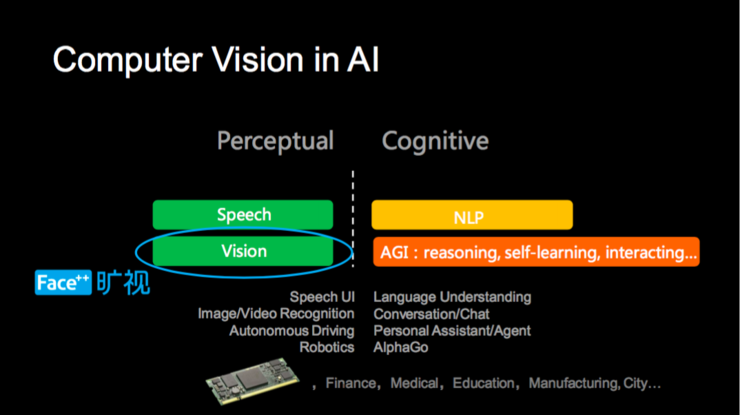
目前人工智能一般划分为感知和认知两块,这一张图可以看到计算机视觉在人工智能领域所处的位置,绿色表示技术上有重大突破或者应用落地相对成熟、橙色和黄色表示还需重大突破。
旷视科技成立至今已经 7 年,一直专注于计算机视觉领域。去年,旷视获得了两个非常好的荣誉,MIT 评选的 2017 年度十大突破性技术中旷视科技的“刷脸支付技术”榜上有名,这是中国公司的技术第一次获此殊荣;MIT 也将旷视列为 2017 年度全球五十大最聪明公司的第 11 位。旷视去年也完成了新一轮 4.6 亿美金的融资,用于做更好、更深入的研究和商业落地。
简单来讲,计算机视觉就是让机器能看。旷视科技自创立就一直在回答“如果机器能自动理解一张图像或者一段视频,我们能做什么?”这个问题。当然这么说比较抽象,其实具体讲我们想做的是“赋能亿万摄像头”。日常生活和各个行业中有很多的摄像头,比如说手机、安防、工业、零售、无人车、机器人、家庭、无人机、医疗、遥感等等。在这些地方,大多摄像头还没智能化,我们的使命是使这些摄像头有智能,不管是在云、端还是在芯片上;我们要构建智能大脑来理解智能摄像头输入的大量信息。

相对于语音识别来说,计算机视觉应用面非常广泛。语音识别的输入和输出较为单一,核心目标是把一段语音变成一句文字。但计算机视觉系统的输出要丰富很多,你需要知道图像/视频里面的物体、运动、场景,其中有什么人、人的位置、行为、表情、注意力等等。你会在不同行业或场景中面临各种各样不同的任务,这也让计算机视觉成为一个很大并增长很快的学术领域(今年计算机视觉年会 CVPR 参会人达到近 7000 人),也诞生出众多的优秀创业公司。

计算机视觉的核心问题包括分类、检测、分割,分别是对一张图、一张图的不同区域和一张图的每个像素做识别。另外如果输入的是视频,我们还需要利用时间关系做识别;其中最核心的是分类问题,因为它是后面三个任务的核心和基础。
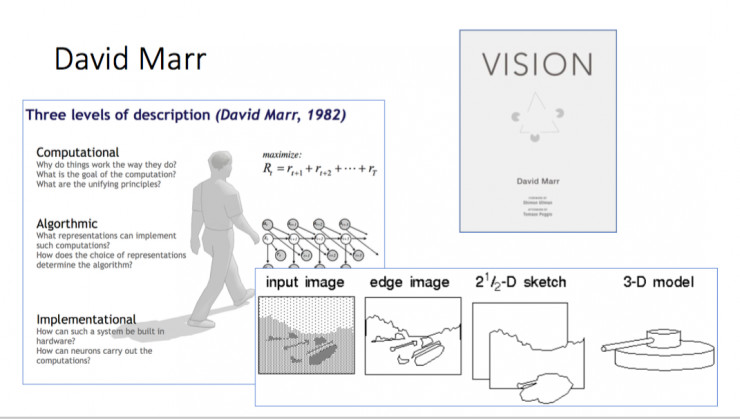
其实,人工智能一出现时,计算机视觉也诞生了。计算机视觉有一个先驱人物叫 David Marr,他在 80 年代初期提出了 Primal Sketch 方法,以及一个研究计算机视觉的大框架,认为图像应该先检测 Edge,然后出 2 ½ D sketch 和 3D 模型。但是 MIT 教授 Marvin Minsky 批评说你这个理论很好,但是忽略了核心问题的研究——如何表述一张图像。

计算机视觉的早期图像表示模型是 Part-based,比如人体可以分解成头、胳膊、腿;人脸可以分解成眉毛、眼睛、鼻子,这样就可以通过 Part 这种组合式的方法表示物体。如果一个物体有结构,这种组合式方法很合适,但很多自然场景的物体没有这么强的结构就不合适了。

80 年代,早期的神经网络也成功运用在人脸和手写数字识别上,但是仅限于这两个领域。2001 年有一个叫作 Viola & Jones 的人脸检测的方法,它先是定义一组 Haar 小波基,然后通过机器学习的方法学习 Harr 小波基的组合来表示图像。这个方法的好处是引入学习来构造图像表示,坏处是它限定在这个小波基上,对有结构的物体做得好,对没有结构的物体就不一定合适了。
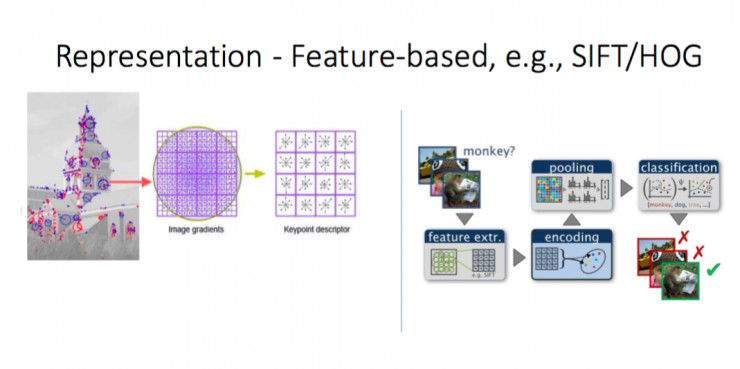
大概在 2000 - 2012 年,在深度学习之前最流行的表示是 Local Feature-based。该方法从一张图片里面抽取数百个 Feature,去人工形成一些诸如 SIFT/HOG 的 Descriptor,编码获得高维向量之后,再送给 SVM 分类器,这是深度学习之前最好的方法。

对人脸也类似。我以前的研究组也用同样方法做过人脸关键点抽取,获得高维 Feature,这也是当时最好的人脸识别方式,但是它有两个大缺点:第一,这个方法整体上是从输入向量到另外高维向量的非线性变换,这个向量的变换次数是有限的,如果真正算它的非线性变换也就三、四次,变多了是不行的,性能不会提高;第二,其中大多数参数是人工设计的,包括 Feature,但人设计复杂系统的能力是有限的。
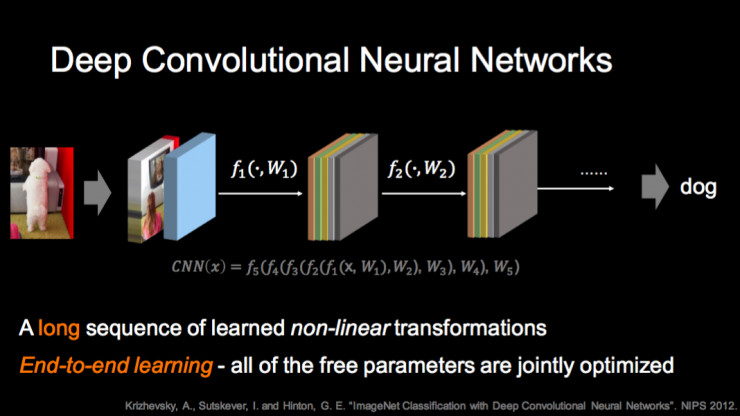
今天的主流方法是深度神经网络,这两个特性就被改变了,整个非线性变换非常长,可以做非常多次,所以系统的表示能力非常强;第二是所有的参数联合训练。这两点让深度神经网络真正能够取得非常好的效果,也包括当时我们在微软提出的 152 层的残差网络 ResNet,第一次在 ImageNet 上超过了人的性能。
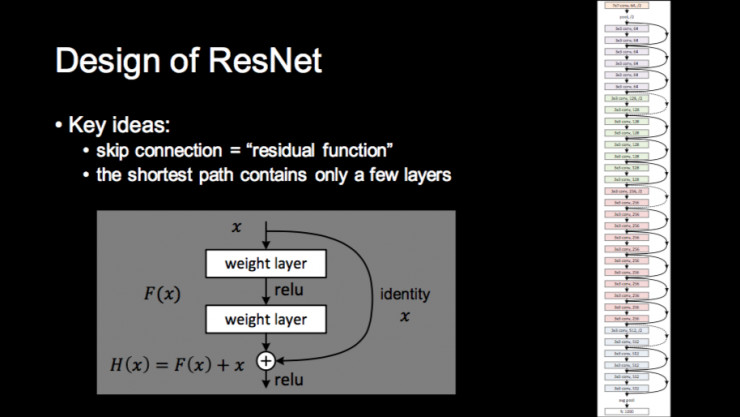
ResNet 为什么能够工作呢?到今天也没有一个明确答案,当然有很多解释。最直观的解释是说当你的非线性变换层数非常多,相邻两层变换的差别就非常小,与其直接学习这个映射,不如学习映射的变化,这样的方式就让整个学习过程,特别是训练优化过程变得更容易。
还有一个解释来自该论文(Kaiming He,Xiangyu Zhang,Shaoqing Ren,Jian Sun. Deep Residual Learning For Image Recognition. CVPR 2016.)的第二作者张祥雨,他认为 ResNet 的整个学习过程是一个由浅到深的动态过程,在训练初期等效训练一个浅层网络,在训练后期等效训练一个深层网络。
论文第一作者何恺明有另外一个更“科学”的解释,他认为整个训练过程相当于深度学习的梯度下降过程中,最为困难的梯度消失问题被 ResNet 解决了,该解释也发表在 ECCV 2016 的一篇论文(Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity Mapping in Deep Residual Networks. ECCV 2016.)中,并在该论文中第一次训练了一个 1001 层的神经网络。
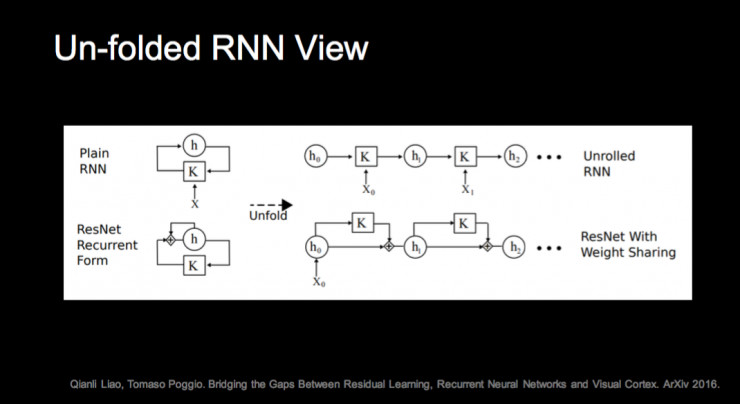
还有一些同行提出的解释。一种是把 ResNet 和 RNN 关联起来,认为如果有 Weight Share, ResNet 可以看作是一种 RNN。还有一种解释把 ResNet 看成是指数多个不同深度网络的集成。用“集成”这个词其实有些问题,因为一般我们做集成算法不联合训练,但这里面整个 ResNet 里指数多个网络是联合训练的,所以很难定义它是不是集成。
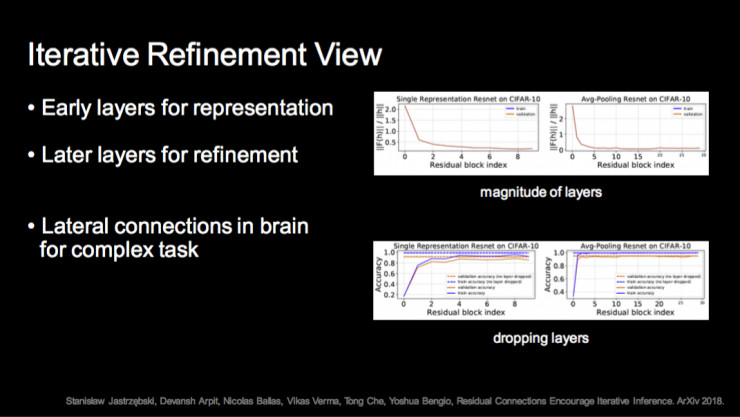
我个人比较认同的一种解释是 Iterative Refinement,它是说网络初期的层学习表示,后期很多层不断迭代和 Refine 这个表示。这跟人理解看图识字很相似,一个不容易理解的东西你要看一会,是基于当前一些已看内容的理解,反复看才能看懂。
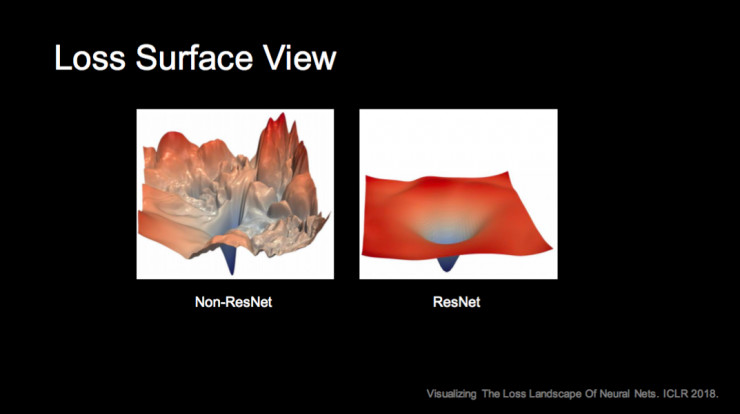
还有从从优化观点的解释,如果不用 ResNet 这种构造,系统的损失函数会非常坑坑洼洼和高低不平,所以很难优化。我们知道整个网络训练是非凸的优化问题,如果是这种不光滑的损失函数,训练很难跳出局部极小;如果是上图右边使用 ResNet 的情况,就可以比较容易地达一个很好的局部极小。最近研究表明,局部极小区域的面积和平坦性和一个方法的推广能力非常强相关。
多层 ResNet 学习高度非线性映射的能力非常强。去年,ResNet 成功应用于 DeepMind 的 AlphaGo Zero 系统中,用 一个40 或 80 层的网络就可以学到从棋盘图像到落子位置这样一个高度复杂的映射,这非常让人吃惊。
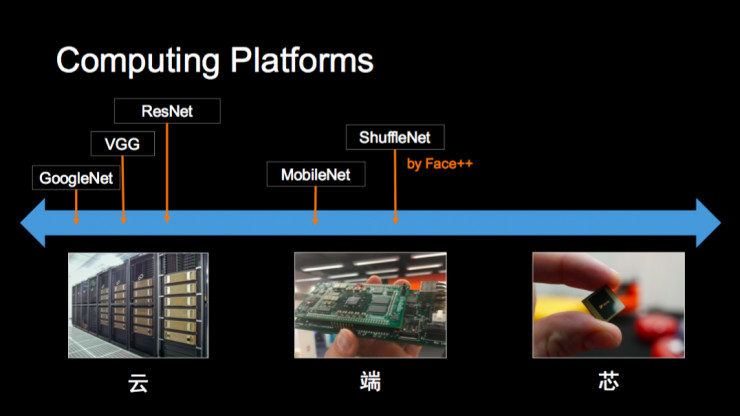
2012 年开始有各种各样的神经网络结构出现。如果从计算平台的角度看这些工作,大概可以分成三类:第一类是在“云”上,像 GoogleNet、ResNet,其目标是向着最高精度方向走,有 GPU、TPU 可以训练非常大的模型,来探知我们的认知边界;第二类平台是在“端”上,特别是一些嵌入式设备,这些设备上的计算能力,内存访问都有限制,但很多真实的场景就是如此,那你怎么去做这上面的研究工作呢?谷歌在去年提出 MobileNet 运行在移动端设备上,旷视科技去年提出 ShuffleNet,其目标是说如何在一个给定计算量的设备上得到最好的效果。
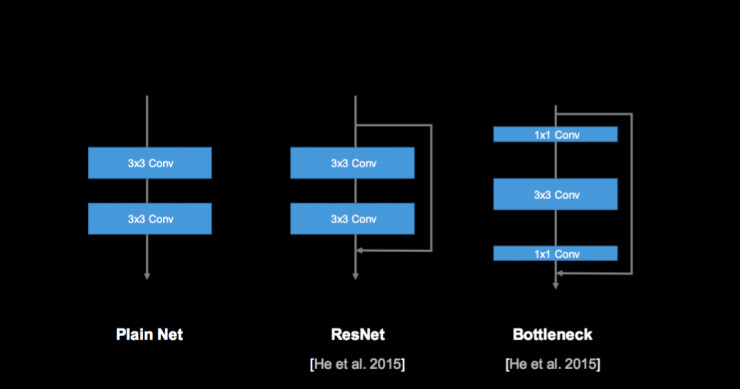
一个网络的最基本结构是多个 3×3 的卷积,ResNet 加了一个跳转连接,我们在 ResNet 中还引入一个 Bottleneck 结构,先做 1×1,再做 3×3,再回到 1×1,这样可以提高卷积的效率。
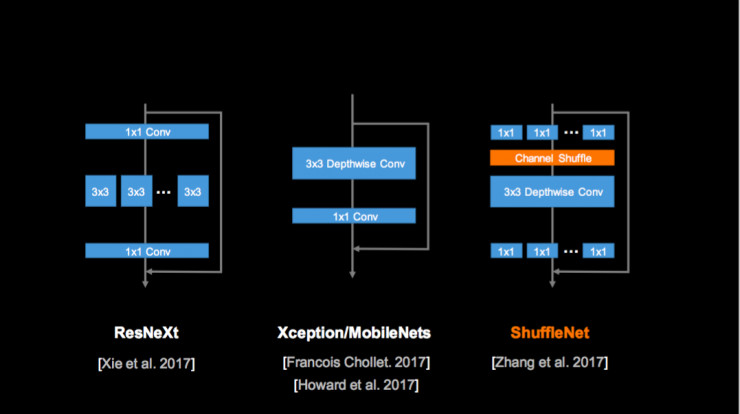
去年何恺明有一项工作叫 ResNeXt,它在 3x3 的基础上引入分组卷积的方法,可以很好地提高卷积的有效性;谷歌的 MobileNet 是一个 3x3 分层卷积的方式,每个层各卷各的,这种方式非常有效,特别是在低端设备上。ShuffleNet 结合分组卷积和分层卷积的思想,对 1×1 Conv 分组;但是如果只分组的话,组间的信息不会交换,这样会影响特征学习,因此我们通过引入 Shuffle 操作,让不同分组的信息更好地交换,然后做 3×3 的分层卷积,再回到 1×1 分组卷积,这就是 ShuffleNet 的核心思想。和其它方法相比,在相同的精度下,ShuffleNet 在真实设备上的速度要比 AlexNet 快 20 倍左右。
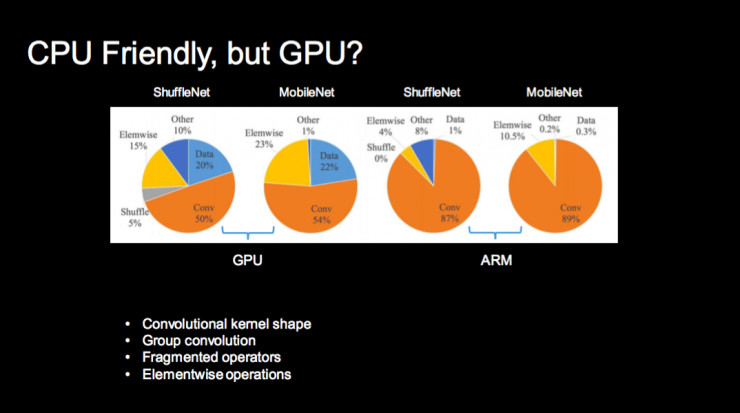
这是我们去年专为手机设计的 ShuffleNet,它在 CPU/ARM 上效果非常好;如果在 GPU 上,它的性能并不好,因为 CPU 和 GPU 的特性不太一样,这里面有很多原因,比如卷积的设计,Group 卷积等等,我就不赘述了。
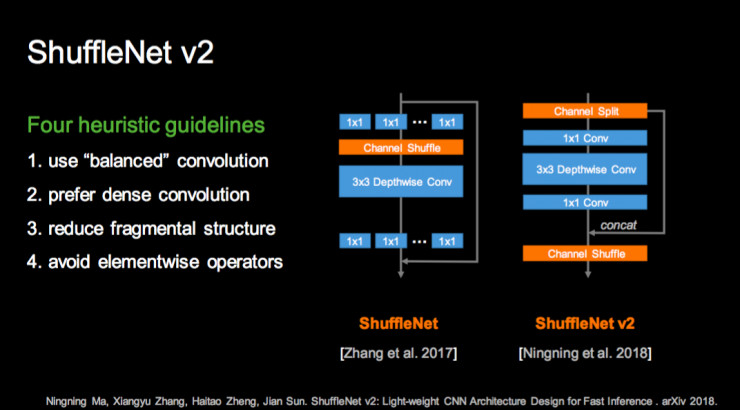
今年我们设计了 ShuffleNet v2,也就是第二版,抛弃分组卷积的思想,引入 Channel Split 和 Channel Shuffle 组合的新方法。这个方法把 Channel 先一分为二,并把每个分支用非常简单的结构来做,然后在用 Shuffle 操作合并 Channel,这样做的根源是我们在网络设计中发现的一些基本指导原则,比如说我们需要平衡的卷积而不是稀疏的卷积,更加规整的卷积而不是零乱的卷积。
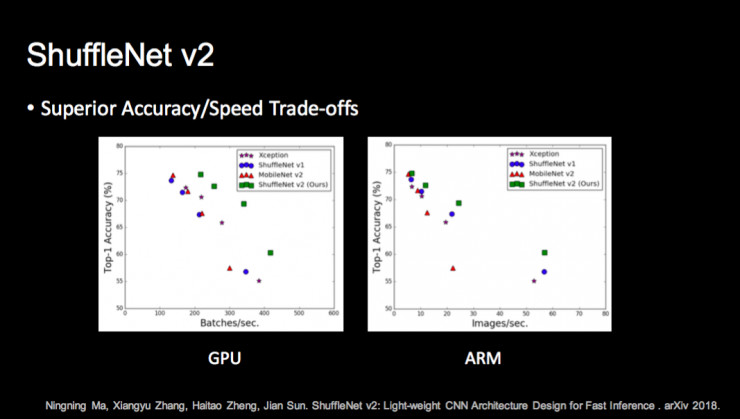
这项工作目前在 CPU 和 GPU 上都获得了最好的精度和速度;不光在小模型,在大模型上同样取得了非常好的效果,上图最后一行是说 ShuffleNet v2 目前在计算量只有 12.7G Flops 情况下在 ImageNet 上取得了非常高的精度。

我们还需要将神经网络运行在芯片上,这不光对网络结构设计有要求,还要对网络内部精度的表示做限制,现在最流行的方法是做低精度化,比如 BNN 和 XNOR Net,还有旷视科技提出的 DorefaNet。低精度方法是指神经网络的权重或激活值用低精度表示,比如 1 位,2 位,4 位。如果可以用低精度表示两个向量,那么卷积计算就可以通过芯片上非常简单的位运算完成计算。
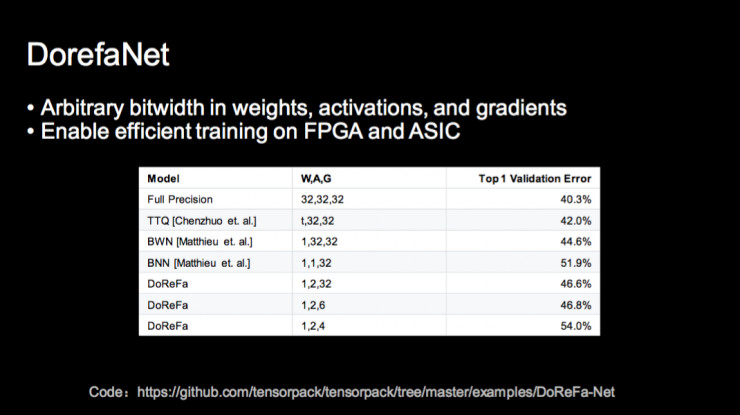
我们提出的 DorefaNet 是第一个对梯度也做量化的研究工作,从而可以让我们在 FPGA 甚至 ASIC 上训练。在这些设备上计算量是一方面,但是它的内存访问限制更大,DorefaNet 这种方法可以做到更好。上图是我们在 ImageNet 上得到的 1 位,2 位,4 位和 6 位量化精度下的最好分类结果。
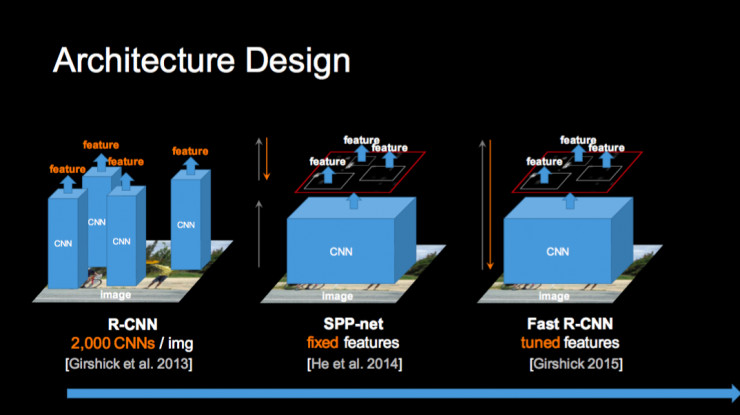
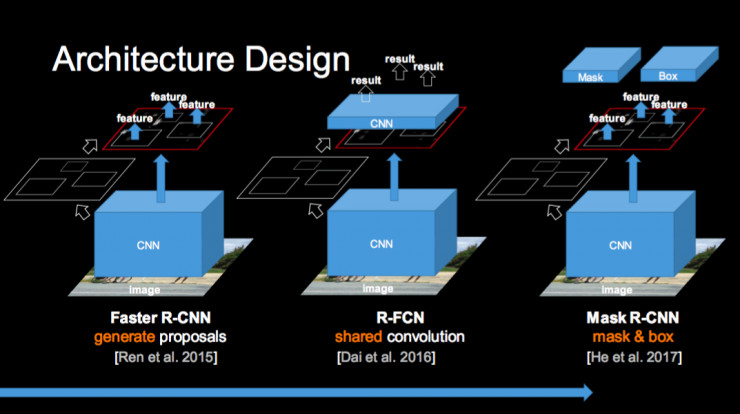
上述分类问题网络设计需要考虑不同的平台,其它问题多是以分类为基础,比如说检测,上图是检测最近几年的发展路程,从 R-CNN 到我们提出的 SPP-Net,到 Fast R-CNN,再到我们提出的 Faster R-CNN,它们都是先应用基础分类网络,然后构建不同的物体检测框架。

检测方面的目前最有权威性的竞赛是 COCO,检测精度用 mAP 来表示,越高越好。2015 年我们在微软亚洲研究院用 ResNet 做到了 37.3,旷视研究院去年参加了这个竞赛,取得第一名的成绩 52.5(满分 100 分),又推进了一大步。我们获得 COCO 2017 冠军的论文是 MegDet。COCO 可以对人进行检测,也可以抽取特征,我们也在研究后者的工作(Yilun Chen, Zhicheng Wang, Yuxiang Peng, Zhiqiang Zhang, Gang Yu, Jian Sun. Cascaded Pyramid Network for Multi-Person Pose Estimation. CVPR 2018.),提取人体骨架,通过骨架表示人体运动,进行行为分析,这样比直接分析图片进行行为训练更为有效。
最后介绍一些我们做的基于云、端、芯上的商业应用。

在云上,旷视科技最早推出了面向开发者的 www.faceplusplus.com 的 AI 云服务。第二个云服务产品是 www.FaceID.com,这是目前最大的在线身份认证平台,为互联网金融、银行、出行等行业提供在线身份认证服务。第三个非常大的云服务产品是城市大脑,它的核心是通过很多的传感器,获取大量信息,最后做出决策。视觉是目前最大的一个感知方式,因为中国有非常多的摄像头,通过赋能这些视觉传感器,我们可以知道人和车的属性,了解交通和地域情况。其中一个很重要的应用是公共安防,即如何用赋能亿万摄像头来协助城市安全和高效运转。

在端上的应用更多,第一个就是手机。vivo V7 是第一款海外上市旗舰机,搭载了我们的人脸解锁技术,还有小米 Note 3 的人脸解锁。我们帮助 vivo 和小米在 iPhoneX 发布之前推出了人脸解锁手机。华为荣耀 V10 和 7C 手机同样使用了我们的技术。华为为什么请孙杨做代言人?因为他长期游泳,指纹已经磨光了,必须用人脸解锁才能很好地使用手机。

不光是人脸解锁,还包括人脸 AI 相机的场景识别,实时知道你在拍什么,更好地调节相机参数,还可以做人脸三维重建,自动实现 3D 光效。另外一个很有趣的应用是深圳和杭州的肯德基旗舰店,消费者可以直接刷脸点餐,这些图是我在现场刷脸支付喝到一杯果汁的过程。第二个是新零售,借助图像感知系统,能把线下的人、货、场的过程数字化。线上零售是数字化的,可以根据数字化的用户统计信息或者个人信息做用户画像、大数据分析,帮助提升新零售效率。我们在线下零售,需要用图像感知来做数字化。

最后是芯片。我们去年在安防展发布了一款智能人像抓拍机——MegEye-C3S,把 DorefaNet 跑在 FPGA 上,再放到相机里,这是业界第一款全画幅(1080p)、全帧率(30fps)人脸实时检测抓拍机。
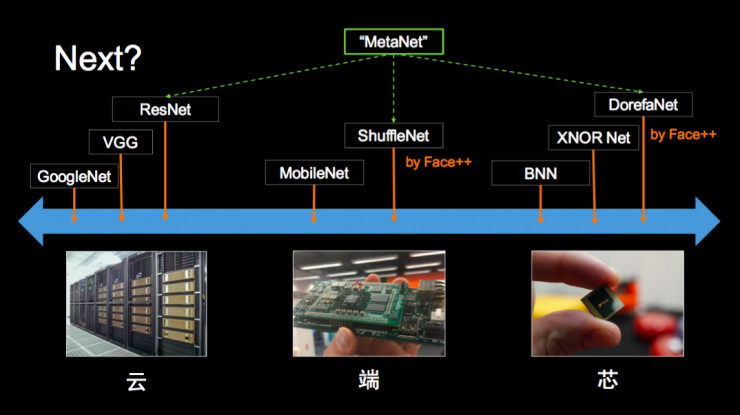
再往下应该怎么做呢?今天我们是分平台,根据平台的特性设计不同的网络。我们相信下一代会有一个“MetaNet”,统一解决各个平台上的神经网络设计和优化的问题。
谢谢大家。










